Hi,
I’ve seen people request a plugin for OBS to remove background (aka Matting) from their camera input. It’s a standard in all video conferencing software today! I also was recording some screencasts with OBS with my video in the corner, and it became instantly obvious how much I need this feature in OBS… So I set out to create one.
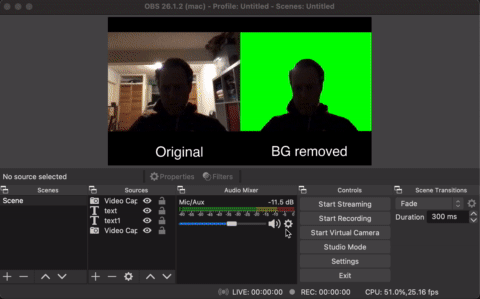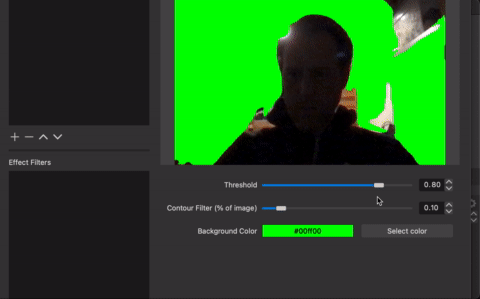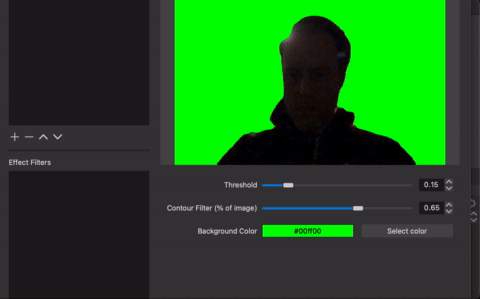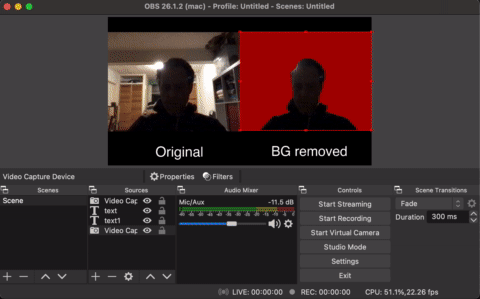
OBS already provide a very convenient plugin template: https://github.com/obsproject/obs-plugintemplate – and it’s implemented in C++, how fun! This is going to be so easy. In C++ I can pull in just about any image segmentation model in any DL framework imaginable. It’s just a question of which one…
Luckily, portrait segmentation has been, at this point, beaten to death by the deep learning community. Models for portrait segmentation are available for free and in masses, and moreover – very highly optimized , small and fast models are available.
One project did a pretty extensive survey: https://github.com/anilsathyan7/Portrait-Segmentation so kudos to you @anilsathyan7 ! Thanks for putting all this together. Anyway, there are plenty of models in that one project alone to choose from. I started by looking at MODNet (e.g. https://github.com/ZHKKKe/MODNet). Seemed decent, but it ended up being dreadfully slow on the CPU. Like 5FPS. So I looked for a speedier model and found SINet: https://arxiv.org/abs/1911.09099 and it has an ONNX pretrained model too, how easy is that? https://github.com/anilsathyan7/Portrait-Segmentation/tree/master/SINet
So, model in the bag, I had to figure out how to run it in the plugin. Getting the raw frames in an OBS plugin filter proved to be not that simple, took me a day, but I cracked it! Learned a lot from https://github.com/obsproject/obs-studio/tree/master/plugins/obs-filters. so:
static struct obs_source_frame * filter_render(void *data, struct obs_source_frame *frame)
{
struct background_removal_filter *tf = reinterpret_cast<background_removal_filter *>(data);
// Convert to RGB
cv::Mat imageYUV(frame->height, frame->width, CV_8UC2, frame->data[0]);
cv::Mat imageRGB;
cv::cvtColor(imageYUV, imageRGB, cv::ColorConversionCodes::COLOR_YUV2RGB_UYVY);
// ... do awesome NN stuff on the RGB image here ...
Note we’re getting YUV422 UYVY, and must convert to RGB. That is if we want our NN to have any chance of working.
This needs to be registered as a “Filter”, which is a kind of “Source”, in the OBS lingo: https://obsproject.com/docs/reference-sources.html and https://obsproject.com/docs/plugins.html#sources. So:
struct obs_source_info test_filter = {
.id = "background_removal_filter",
.type = OBS_SOURCE_TYPE_FILTER,
.output_flags = OBS_SOURCE_VIDEO | OBS_SOURCE_ASYNC,
.get_name = filter_getname,
.create = filter_create,
.update = filter_update,
.destroy = filter_destroy,
.filter_video = filter_render,
.get_properties = filter_properties,
.get_defaults = filter_defaults,
};
Note I’m using the .filter_video property. The .video_render will bring you no joy! It’s pretty much only for using shader-based effects, and you won’t be able to access the raw data.
Now to run the ONNX model! I looked (well, let’s be honest, I ripped it off) at the ONNX runtime inference examples for C++ https://github.com/microsoft/onnxruntime/tree/master/samples/c_cxx – they were simple enough to replicate (rip off). I just streamlined it a bit, and saved all that which I needed in a struct that will stay alive during the plugin’s life:
struct background_removal_filter {
std::unique_ptr<Ort::Session> session;
std::unique_ptr<Ort::Env> env;
std::vector<const char*> inputNames;
std::vector<const char*> outputNames;
Ort::Value inputTensor;
Ort::Value outputTensor;
std::vector<int64_t> inputDims;
std::vector<int64_t> outputDims;
std::vector<float> outputTensorValues;
std::vector<float> inputTensorValues;
Ort::MemoryInfo memoryInfo;
};
Phew, that’s a lot of stuff to save! But alas we need (pretty much) all of it for inference.
So the initialization of the network kind of goes like
std::string instanceName{"background-removal-inference"};
char* modelFilepath = obs_module_file("SINet_Softmax.onnx");
blog(LOG_INFO, "model location %s", modelFilepath);
tf->env.reset(new Ort::Env(OrtLoggingLevel::ORT_LOGGING_LEVEL_ERROR, instanceName.c_str()));
Ort::SessionOptions sessionOptions;
sessionOptions.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
tf->session.reset(new Ort::Session(*tf->env, modelFilepath, sessionOptions));
bfree(modelFilepath);
Ort::AllocatorWithDefaultOptions allocator;
tf->inputNames.push_back(tf->session->GetInputName(0, allocator));
tf->outputNames.push_back(tf->session->GetOutputName(0, allocator));
// Allocate output buffer
const Ort::TypeInfo outputTypeInfo = tf->session->GetOutputTypeInfo(0);
const auto outputTensorInfo = outputTypeInfo.GetTensorTypeAndShapeInfo();
tf->outputDims = outputTensorInfo.GetShape();
tf->outputTensorValues.resize(vectorProduct(tf->outputDims));
// Allocate input buffer
const Ort::TypeInfo inputTypeInfo = tf->session->GetInputTypeInfo(0);
const auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo();
tf->inputDims = inputTensorInfo.GetShape();
tf->inputTensorValues.resize(vectorProduct(tf->inputDims));
// Build input and output tensors
tf->memoryInfo = Ort::MemoryInfo::CreateCpu(
OrtAllocatorType::OrtDeviceAllocator, OrtMemType::OrtMemTypeCPU);
tf->outputTensor = Ort::Value::CreateTensor<float>(
tf->memoryInfo,
tf->outputTensorValues.data(),
tf->outputTensorValues.size(),
tf->outputDims.data(),
tf->outputDims.size());
tf->inputTensor = Ort::Value::CreateTensor<float>(
tf->memoryInfo,
tf->inputTensorValues.data(),
tf->inputTensorValues.size(),
tf->inputDims.data(),
tf->inputDims.size());
That’s a mouthful. I mean seriously, ONNX – can you streamline this a bit? It’s a lot of verbose code for very little utility… it’s OK though.
Now – for inference – to the filter_render() function-mobile!
// Prepare input to nework
cv::Mat resizedImageRGB, resizedImage, preprocessedImage;
cv::resize(imageRGB, resizedImageRGB,
cv::Size(tf->inputDims.at(2), tf->inputDims.at(3)),
cv::InterpolationFlags::INTER_CUBIC);
resizedImageRGB.convertTo(resizedImage, CV_32F);
cv::subtract(resizedImage, cv::Scalar(102.890434, 111.25247, 126.91212), resizedImage);
cv::multiply(resizedImage, cv::Scalar(1.0 / 62.93292, 1.0 / 62.82138, 1.0 / 66.355705) / 255.0, resizedImage);
hwc_to_chw(resizedImage, preprocessedImage);
tf->inputTensorValues.assign(preprocessedImage.begin<float>(),
preprocessedImage.end<float>());
// Run network inference
tf->session->Run(
Ort::RunOptions{nullptr},
tf->inputNames.data(), &(tf->inputTensor), 1,
tf->outputNames.data(), &(tf->outputTensor), 1);
Ha! Good ol’ OpenCV to the rescue. Not a ton going on here, just resizing and converting to float and normalizing (mean, variance).
Next up, we apply the mask to the output:
// Convert network output mask to input size
cv::Mat outputImage(tf->outputDims.at(2), tf->outputDims.at(3), CV_32FC1, &(tf->outputTensorValues[0]));
cv::Mat outputImageReized;
cv::resize(outputImage, outputImageReized, imageRGB.size(), cv::InterpolationFlags::INTER_CUBIC);
cv::Mat mask = outputImageReized > 0.5;
We’re pretty much done here. But WAIT! We have RGB output , and OBS is expecting YUV422 UYVY. But wait again! OpenCV doesn’t have any cv::COLOR_RGB3YUV422_UYVY built in conversion – wth are we supposed to do??
Not to worry, here’s a useful snippet for ye:
void rgb_to_yuv422_uyvy(const cv::Mat& rgb, cv::Mat& yuv) {
assert(rgb.size() == yuv.size() &&
rgb.depth() == CV_8U &&
rgb.channels() == 3 &&
yuv.depth() == CV_8U &&
yuv.channels() == 2);
for (int ih = 0; ih < rgb.rows; ih++) {
const uint8_t* rgbRowPtr = rgb.ptr<uint8_t>(ih);
uint8_t* yuvRowPtr = yuv.ptr<uint8_t>(ih);
for (int iw = 0; iw < rgb.cols; iw = iw + 2) {
const int rgbColIdxBytes = iw * rgb.elemSize();
const int yuvColIdxBytes = iw * yuv.elemSize();
const uint8_t R1 = rgbRowPtr[rgbColIdxBytes + 0];
const uint8_t G1 = rgbRowPtr[rgbColIdxBytes + 1];
const uint8_t B1 = rgbRowPtr[rgbColIdxBytes + 2];
const uint8_t R2 = rgbRowPtr[rgbColIdxBytes + 3];
const uint8_t G2 = rgbRowPtr[rgbColIdxBytes + 4];
const uint8_t B2 = rgbRowPtr[rgbColIdxBytes + 5];
const int Y = (0.257f * R1) + (0.504f * G1) + (0.098f * B1) + 16.0f ;
const int U = -(0.148f * R1) - (0.291f * G1) + (0.439f * B1) + 128.0f;
const int V = (0.439f * R1) - (0.368f * G1) - (0.071f * B1) + 128.0f;
const int Y2 = (0.257f * R2) + (0.504f * G2) + (0.098f * B2) + 16.0f ;
yuvRowPtr[yuvColIdxBytes + 0] = cv::saturate_cast<uint8_t>(U );
yuvRowPtr[yuvColIdxBytes + 1] = cv::saturate_cast<uint8_t>(Y );
yuvRowPtr[yuvColIdxBytes + 2] = cv::saturate_cast<uint8_t>(V );
yuvRowPtr[yuvColIdxBytes + 3] = cv::saturate_cast<uint8_t>(Y2);
}
}
}
Might not be a looker, but it’ll get the job done. It could obviously be parallelized, like these guys are talking about: https://stackoverflow.com/questions/49964259/cpp-rgb-to-yuv422-conversion (I put my code also up there as an answer, plz upvote kthx)
So we just about done here. We can add some embellishments like sliders to set the detection threshold, and doing some contour filtering. Really just something for the folks to toy around with…
static obs_properties_t *filter_properties(void *data)
{
obs_properties_t *props = obs_properties_create();
obs_property_t *p_threshold = obs_properties_add_float_slider(
props,
"threshold",
obs_module_text("Threshold"),
0.0,
1.0,
0.05);
obs_property_t *p_contour_filter = obs_properties_add_float_slider(
props,
"contour_filter",
obs_module_text("Contour Filter (% of image)"),
0.0,
1.0,
0.025);
obs_property_t *p_color = obs_properties_add_color(
props,
"replaceColor",
obs_module_text("Background Color"));
UNUSED_PARAMETER(data);
return props;
}
Yeah. OBS plugin C code. I liked it, but — IDK if I’m coming back for more.
Worked out OK in the end though: https://github.com/royshil/obs-backgroundremoval
I put it on the OBS forums as well: https://obsproject.com/forum/resources/background-removal-portrait-segmentation.1260/
Right, Off I go!
Roy.